Agents, Open Agent Architecture, and Open Hyperdocument System Adam Cheyer. 1.* - unedited transcript - Thank you. IÂ've been at sri previously and have been following DougÂ's work for a while. I wanted today to say a few words about agents, and say a few words about my experience, also bring something to the party. So today we can download WBI and print and other things, so IÂ'll try to include one piece for people to look at. And then what IÂ'm going to try to do is to suggest, after talking about a lot of future stuff that we could do, try to start a discussion on what I think we should to today to move a step forward. So what could we do to start creating an open source OHS system? And itÂ'll be my perspective and controversial, perhaps, but weÂ'll take it from there. [aside] So, oh. You forgot to tell me about that problem. So it looks like that slide Â- what I wanted to do was say that the word Â'agentÂ' actually means many different things to many people and when you go to an agent conference these days you have to ask, "what do you mean by agents" and find out what theyÂ're saying. So I had this great picture with lots of examples of different types of things people are calling agents, so I guess IÂ'll run through them verbally and hopefully weÂ'll update the website and people can go back and look at that later. ENGELBART [offstage]: Something happened to the server at 6:30 this morning and his text disappeared and IÂ'm not smart enough to know what to do about it. [Some techies give suggestions to fix the problem but it doesnÂ't work] CHEYER: Okay, but anyway I can describe what IÂ'm talking about. So as I can clearly see, there are many types of agents. Here are some of the properties that people are talking about with agents. Some people say that agents are mobile pieces of code that move under their own power from place to place. So this is really about mobility. Examples of such applications areÂ. General Magic I guess, was one of the pioneers and holds the patent for this type of mobile code, but things like Telescript from General Magic, DAgents in the research community, and a number of others are focusing on how do you move code from place to place and what efficiencies do you get? Other types of agents are called autonomous agents that have to react and deal with unexpected occurrences such as slides disappearing in the middle of a presentation and these are typically based on reactive planning technologies. You see incarnations in physical robots. So this is a whole community of agent researchers who are totally different from some of the other agent researchers weÂ'll describe later. Some people, for instance, from MIT Â- Patty Maas Â- has focused on learning in agents and has trying to share opinions or trying to have collaborative filtering, sharing opinions, and thatÂ's what they target as agent systems. Some particular groups such as Microsoft consider agents to be visible and interactive and perhaps dialogue with natural language so, for instance, Microsoft Agent is a graphical animated character such as youÂ'll find in their office products that can take a more human appearance. And finally down at the bottom of our picture. This will get to the kind of work that weÂ've been looking into and that would be communities of agents, or distributed agents. And the idea is that todayÂ's distributed object systems are very often brittle. Can we actually have a dynamic, changing, heterogeneous, distributed, cooperation and competition going on but with computational elements? So how does this relate at all to DougÂ's Open Hyperdocument System? I want to bring up the point that today weÂ've been talking a lot about, or, in the past weÂ've been talking a lot about document management: a community needs to publish documents and information. But we should also think about how could we manage services, so it could be any computational element. So I donÂ't know, it could be a compile button or a summarizing program or a great artificial intelligence or a non-artificial intelligence programs. How can we bring in services into what weÂ're building for this state?
What IÂ'd like to bring to the table would be that someday maybe contribute is something called Open Agent Architecture. What weÂ've been looking at is how are we going to create distributed applications or systems which are composed of a number of processes that are cooperating and competing and can come and go and work together in a more dynamic way. IÂ'm not going to talk a lot about this but the term weÂ've been using is delegated computing. The idea is, if you have Â- typically in distributed object technology today, like Genie or CORBA or messaging systems, one object, a client, needs a service from another object, the provider, and thereÂ's code in the client to be able to find the object and call it, and thatÂ's very inflexible. If now you have hard coded logic in the control of the client for how itÂ's going to interact with others, and with delegated computing, the key idea is: can I describe a task that can be at arbitrary levels of detail? If I wanted to know exactly how itÂ's done, I can say that. If I donÂ't care then here, I want to do this, you agents will work on this task together, and clearly you can see how humans can become part of the loop. Anyway um, weÂ've had over the years built some 40+ applications and have built lots of technology, some AI and some not into some agents that could communicate and dialogue. Papers on this and software can be downloaded in near open-source, not true open source, from openagent.com, which is just an easy reference to SRIÂ's pages on this matter. Through this infrastructure, what we were trying to do is as Doug said, we donÂ't want to have the AI programs just solve all problems we were looking at how to build distributed flexible systems and how do humans interact if you have this distributed, delegated, wonderful blob of computational power?
How will humans interact with it? On the left side of this slide you see some of the dimensions weÂ're working at. We want to be able to access our information and services from anywhere. If I have a telephone, I want to be able to speak to it and pull up things from my desktop or other websites. If we have a desktop machine, I can visually see the answers. If I have both, then how do I manage the combination of speaking and using the available resources? This is an example of something that would be very hard to do if you had to code every possibility. Delegated computing simplifies this task. Another dimension would be multimodal interfaces. What does this mean? When IÂ'm talking with you, IÂ'll be pointing and circling and gesturing and speaking and writing all together; itÂ's a great way for humans to talk to humans. What we were looking was how do we delegate the task among a community of agents. Another dimension that we were looking at is in such an architecture if a human can talk to all the agents and the agents are cooperating and communicating with each other, it would be great if multiple humans could come together in the same place, work on problems where some automated systems are doing some work, some humans are doing some work Â- and we have several applications looking at that. Next to mention we looked at Avatar. This was the Microsoft agent idea. Some systems today, the humans are always in control: do this, get this, this is what I want. Well, if you introduce more social elements into computing, some avatars or agents might give suggestions or watch what your doing and give criticisms and help you dialogue or answer questions and take you on tours, explain things for you. So the social dynamic, especially when multiple people are working together, agents have to obey some of the social conventions Â- how does that work and where do the problems arise from that? Finally, some of our latest applications weÂ're looking at: augmented environments. This means my place in this giant community world, my physical location have an impact with what IÂ'm dialoguing with. So if IÂ'm walking down a hall, information should be appearing contextually according to what IÂ'm doing at that moment and where I am and who I am. Again, a very hardcoded approach would be very difficult to take and delegated computing was a way of studying sort of a continuum of how people and agents could work together on a space and some of the readings and the software we have can be downloaded, and maybe we can in the future pull this into our communities of knowledge and services.
So finally IÂ'm going to take Â- IÂ've been sort of watching Doug and DougÂ's group for about a year and a half and we all agree we want to create something; software that takes some of these wonderful ideas, modernizes them with the appropriate standards. The problem is that there is so much to do and so many different ways to do it, itÂ's hard to get enough consensus to move forward. This is an issue. What I wanted to do was put forward Â- this is my particular take and Doug gave me permission to speak and say this, but are there ways, which we can agree on? Can we find something that we agree on that we donÂ't have to do massive amounts of coding but we can at least move in the right direction? And it may not solve all problems but maybe we can come to a consensus on those. So the first thing is when I first heard about the Open Hyperdocument System was I said, great, tell me what it is and IÂ'll code it up in a weekend, how hard could it be? [laughter] The more I learned about it, I said, oh, this is boring, and every time I made a proposal, well, what about this aspect? So my idea is that we need to have a target and for me, it has to be different enough than what we can do today and it is always a very tricky thing to do because pieces exist. I want to have an Augment-like system that can manage four types of documents: email, so sort of like hypermail, existing web pages, Augment files, and source code. Source code so we can continue work in it. And I want to have a web browser where if we have these four things, and we have hyperlinks to the specifications, which have discussions and annotations to what we should do next, and so already those four things might be enough to get us going. And the actual capabilities Â- so this is not the actual full-blown OHS Â- but I want publishing Â- we want to be able to publish back to the server somehow Â- version control would be great, especially if weÂ're going to do source code. We need to have the adaptable views Â- being able to see things in different ways Â- because that I think is really key to what IÂ've seen; one of the key elements in DougÂ's works, and we need to be able to have an editor to be able to publish it back in. So I was trying to look at all the ways we could accomplish these things. The first thing I said was XML, the documents we manage Â- I feel strongly about it Â- XML is the way to go. Now there might be some argument about it, but I feel that this is going to be the future of the web. ItÂ's structured, thereÂ's not that many choices Â- can we all agree on that, weÂ'll take this offline, but IÂ'm going to put that forth. To do that that means thereÂ's some tasks involved. To get those documents that means weÂ're going to need some sort of translators in some form that we can store things in them in some form of XML-like content. So how do we get from source code to XML for some language that weÂ're developing, you know, or languages? Also we need some translators for DougÂ's work, you know, the Augment files; itÂ's got all the right properties: we need to define a schema that would meet these minimal criteria, right translators, and we can get a body of documents that we can work with. Step 2 is publishing. So I looked around; how do you publish documents on the web? IÂ'd seen thereÂ's http where thereÂ's a put command but the best standard, which is from the ITEF effort, is something called WebDav, and I havenÂ't seen much discussion on this yet, but it stands for Web-based Distributed Authoring and Versioning. So IÂ'm like, whoa, that sounds like what we need and from what IÂ've seen, itÂ's not completely finished. The versioning, for instance, hasnÂ't been truly linked in but itÂ's much better than httpÂ's put, which is the only other real good way for publishing things. So the next hard stance will be, letÂ's use WebDAv for the method of publishing. LetÂ's encourage and work with them to head it in directions that we want, but there are a lot of products already on the server side. There was something somebody mentioned called ZOPE? Which was an application server written in Python? I donÂ't know how this might go because Python isnÂ't as widely accessible. I want to use WebDav, we might go with ZOPE, and apache already has a WebDav publishing module that might be even easier. None of these integrate with CVS and version control but weÂ'll find a way to add them in later. The next step is views; how do we do dynamic views? Doug already showed this by using proxies. Originally I was thinking we should build our entire client editor browser from scratch or use Netscape and I was looking at this but my standpoint now Â- itsÂ' debatable Â- is that we should just use existing browsers now for the first try, use proxies to translate into XML for the different views. What proxy to use? WBI is a great one; another way of doing the same kind of thing would be to use something like servlets. An XSL is a w3c recommendation for how to translate XML documents into something. Well, thatÂ's what we need. And so John Bozak might be able to help. So one question might be: is there some sort of WBI/XML integration? There is? Oh, excellent, weÂ've just solved our problem so maybe WBI/XSL is the consensus weÂ'll arrive at. The next step would be editor because there needs to be some way to publish this through WebDav. Now again, we could Â- in DougÂ's model and world, it is an integrated editor/browser Â- so my recommendation at the moment after thinking about it in various ways is that IÂ'm going to take Caveat and I see some questions, but let me just finish and weÂ'll open the dialogue. But at the moment I want any browser or a modern browser, more or less, to be involved so what I was going to suggest was letÂ's let views be in any browser and when weÂ're ready to edit, weÂ'll submit somehow at the same way we request our views Â- and we can talk about how to do that afterwards Â- up to our proxy. WeÂ'll say, weÂ're ready to edit my document and some window will appear, some java-based XML editor that is enabled with WebDav. So there are open-sourced java based XML editors, thereÂ's freely available java connectors to WebDav. ItÂ's an accommodation but it should allow anyone to quickly be able to take a document that weÂ're controlling and then publish it back using WebDav. And the final bullet that I thought: if weÂ're going to do source code, for instance, then weÂ're going to need a way of sticking actions of a certain type, associating actions with a document type. So if I have a source code, I want to have a compile button somewhere; if I have a make file then IÂ'd want a make command somehow; for a regular document IÂ'd like to spell check it or somehow bring in some other sources of information through proxies. IÂ'm not quite sure exactly how to solve this problem but I donÂ't think it can be that hard. So a way of specifying how actions can be brought into this mix and associated with documents; thatÂ's kind of a poor manÂ's Open Hyperdocument System that moves in the directions Â- IÂ'm taking a hard stance on a few things: proxies, any browser, WebDav Â- there are pointers that we have to argue on, but you know, thatÂ's just whatÂ's there. Thank you. [
---
Above space serves to put hyperlinked
targets at the top of the window
|

 Fig. 1
Fig. 1 Fig. 2
Fig. 2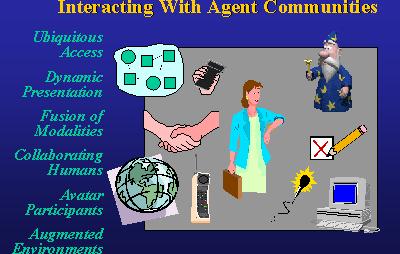 Fig. 3
Fig. 3