Creating a SuperNews Group Eric Armstrong. 1.* - unedited transcript - Hi. So the title is Creating A Super News Group, which has probably got to be one of the worst titles for a project that anyone ever came up with. It could really use a better idea. I just saw on the e-mail list this morning hyper mail, or hyper news, which is a great name. I wish I would have thought of it. In the fifth section of this colloquium I presented an idea that what we should really target for development of DKR is open source development. Because doing that would give us maximum leverage to building the kind of systems we need for all the other areas and I focused a lot in that talk on the advantages of using hyperlinks and hierarchical structuring for source code. So there is a big picture that we want to get to. A product or a mechanism that will enable a wider universe to be more effective. Now taking from there I want to focus in now, what is the smallest core nucleus that we can build that will help us to get to the target place? The reason for getting a small nucleus is several folds. You want something that is going to be useful as soon as possible so you can use it do to your own design with. You want something that will be widely useable. A news group of some kind is going to be useable by everybody, not just source development. And by giving you a highly constrained initial target it ups your chance for success. The reason for that is if you are dealing with a complex area, design and development is a process of exploration and discovery. ItÂ's not an assembly line process of simply spec it and builds it. So you reach it. You design a very simple system, you build features for it. To get to the next level you have to redesign. You redesign that level and you keep the same features until you test it and you know itÂ's working, and then you add the features that new design allowed you to add. You ratchet your way up to the larger picture and that gives you the ability to expand from there.
Now this all started with DougÂ's observations that hey, we already have an e-mail archive that is in HTML form. I happen to think that is a great achievement because translating plain text into HTML in an intelligent way is not an easy problem to solve, but they have done that. If we add an intermediary he suggests we can add the kinds of links that augment gives you and take advantage of what they have already deduced as being necessary in this domain. What really got them excited is they realized hey, if we did that we could probably use that for any HTML page out there, and change the way people use the web. So that is an intriguing prospect, and it convened a whole bunch of us here together to start talking about it. There was an interesting thing in the news paper the other day that if you get six engineers in a meeting, you probably get about twelve opinions. This is no different. We had a lot of interesting ways to go about the project. We also had a convergence on a couple of key areas that make since. Again, it emphasizes the fact that we need this system to explore the design space. We need something along these lines that will help us be more intelligent on how we carry on the discussion.
We want to be able to do it remotely so that people out in the web space will be able to get the best brains in the world out on the project. It is infinitely better than even the best brains in this room, which is considerable. The one challenge said hey, how about if you guys that are there, physically adjacent, put together an initial system that we can then make use of to design the next version, because it is really hard to get started with the tools we have at our disposal today. Now if we take this task, we begin, what we want to do really is to eliminate the copy redundancy in the e-mail archives. .
What happens when you get e-mail is to reply to it, you have a copy of it, you insert your comments and now all the old stuff is still all there. It makes it very hard to search to reuse the content. With this kind of a mechanism you get sort of documents that grow organically, people add to them. Now IÂ'm not addressing here some of the issues that you really want to do at some point is to distill the documents. You want them to grow, but you also want a distillation process. ThatÂ's the second sort of mechanism that has to come after this one.
So the data model you get when you look at an HTML document is a structured document on the left, it is called a document object model, in XML/HTML terms. Actually it goes deeper than this. Each block there is sort of a unit of structure in this sense. What you want to do is respond to an element in that message, not have to respond to that message as a whole. That eliminates the copy redundancy. You already have threading in your mail list of clients hopefully, and what we simply want to do is add that hierarchy, bring it down to the level of the message, and take advantage of the same facilities. Now the response is again also a tree of, each of which has itÂ's own responses.
So here is an idea of what it may look like. On the left is an HTML document, as it would normally appear in a browser. We added some plusses there. Those are similar to the kinds of icons in the augment system. If you switch to an outline view you would simply see H1 and H2 tags, you see those on the top right, or switch to the single line view, which gives you a little more information. WhatÂ's interesting here is that in that single line view, again that hierarchy is not clear, looks like the list of folders in your directory structure, or in your mail processor. Moving forward from there.
We do one more thing with the intermediately processor, which is to add those little links at the end which are self referential to point to that paragraph. That lets you copy them, put them into your own message, or it allows for the client that is dealing with this system to intelligently respond, to identify the piece of the message that you are responding too.
So in this kind of a system, when a couple of people respond to you it could look a little something like this on the left. Fred responds just like in an e-mail message. ItÂ's attributed, you know whom it came from, and itÂ's in line, it is in context. It is not disassociated from the text it was originally referring to. Or you might have a button at the end that you click to hide those things. You see the original message rather than the responses.
Or another option was that you might have an icon for individual messages and they could show up in another window. The point being thatÂ.IÂ'm racing. IÂ'm going to quit in another couple of slides. The point being that you have different client potentials that you could build on the same fundamental system, and you want that flexibility.
The third item there is that you want to create an open standard. The reason for that is that it lets lots of people get into the game. You want lots of people devising servers, devising clients, coming up with the best possible interaction mechanism. What we come up with may or may not be the best, given 100 organizations out there doing the same thing. One of them is going to emerge as a winner. You want to preserve attributions, preserve discussions, and be able to reuse them.
Several things you donÂ't want to address right up front are those things that make the problem too complex to solve. You donÂ't know the answers offhand. There are a lot of things you have to leave out of Version 1.
Architectural components that weÂ've looked atÂ. intermediate processingÂ. the web lets are a great way to get your hands on that DOM and modify it inside the context of a browser or as a stand-alone application. XUL is another mechanism thatÂ's being developed as part of the Mozilla browser.
We identified three development stages. First is simply browsing, to be able to look at it. Get those features.
Second is if you maintain a local copy you get interesting capabilities, such as you already have in your email. Be able to highlight the new and unread portions of a document. So when an update comes in, you automatically know what you havenÂ't read yet. Another is now you can say "I want to ignore this whole thing" or "I want to see just new versions of this document" or "I want to follow all of the discussions in my inbox."
Finally, thereÂ's a more integrated editing system. You need versioning and stable anchors. IÂ'm going to end here, so that everyone else gets a chance to spend a few minutes. The rest of the seven slides are just a review of some of the design options we looked at. Again, there are multiple ways to skin the same apple. We need a system like this ourselves to make sure we intelligently explore the design space. (Applause) Seven slides showing design options:
[
---
Above space serves to put hyperlinked
targets at the top of the window
|

 Fig. 1
Fig. 1 Fig. 2
Fig. 2 Fig. 3
Fig. 3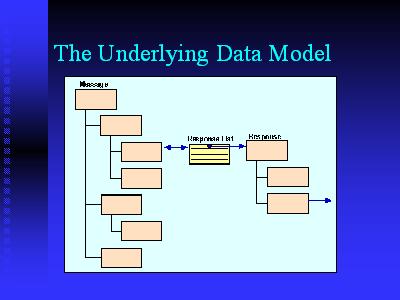 Fig. 4
Fig. 4 Fig. 5
Fig. 5 Fig. 6
Fig. 6 Fig. 7
Fig. 7
 Fig. 8
Fig. 8 Fig. 9
Fig. 9 Fig. 10
Fig. 10 Fig. 11
Fig. 11 Fig. 12
Fig. 12
 Fig. 13
Fig. 13
 Fig. 14
Fig. 14 Fig. 15
Fig. 15
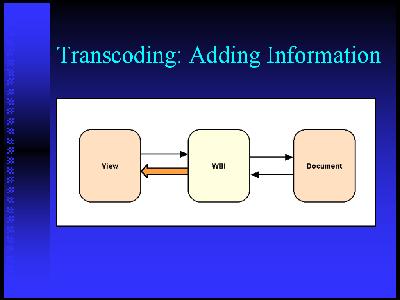 Fig. 16
Fig. 16
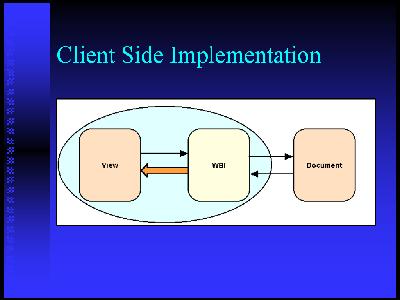 Fig. 17
Fig. 17
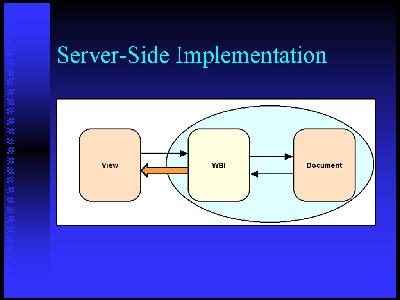 Fig. 18
Fig. 18
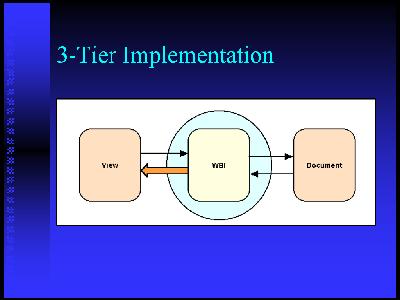 Fig. 19
Fig. 19
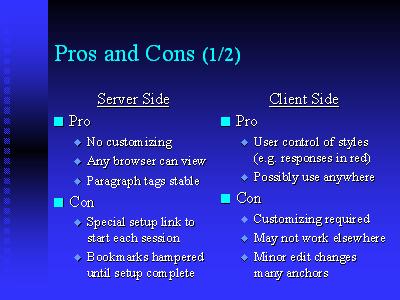 Fig. 20
Fig. 20
 Fig. 21
Fig. 21